Grep程序在谷歌的MapReduce论文中也作为示例程序提到过,在大规模数据集中并行找出符合指定模式的文件。
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
按照官方指南,只需要在hadoop安装目录下用hadoop程序就可以作为单机来跑hadoop
按照官方的指南,跑一个简单的grep程序,具体的jar包得看使用的自己使用的版本
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.0-SNAPSHOT.jar grep input output 'dfs[a-z.]+'
$ cat output/*
启动jvm的调试功能,只需要在hadoop-env.sh中添加
export HADOOP_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005"
(这部分是jvm调试相关)
在idea中打上断点,通过查看haoop-mapreduce-examples模块中的pom文件,可以看到在打包插件里指定了org.apache.hadoop.examples.ExampleDriver类为启动类。
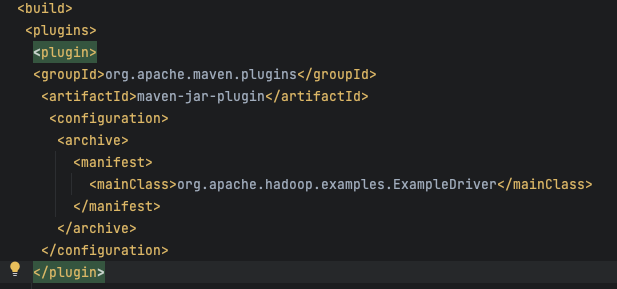
那么就从这个类开始分析吧。
ExampleDriver这个类是用来将各种测试类注册进去并加上一些文字性描述,能看到自带了很多实例程序,我这次分析的是grep程序,对应注册的是Grep类。
ExampleDrive类中使用ProgramDriver类,这个ProgramDriver中使用一个map保存测试类和他们对应的名字关系,而测试类在ProgramDriver中被解析成ProgramDescription,ProgramDescription中保存了测试类的main方法和描述,然后测试时,比如我们的grep程序,先用grep这个名字找到对应的ProgramDescription然后直接调用main方法把命令行中的剩余参数传入。
接下来看一下Grep中的main方法
main方法中用了一个ToolRunner去run,run方法中提供了Configuration类,Grep类,和参数,能猜到应该是使用了默认的配置项去调用Grep,能看到这里的核心是一个Tool接口,Grep继承了Tool接口,ToolRunner会运行Tool。
根据javadoc看看Tool是什么
看样子hadoop为了方便测试写的一个接口,把一些环境的初始化配置隐藏起来了。
那来看看Configuration是什么,这个应该是核心类
这个Configuration就负责加载core-site那些配置文件已经用户程序中设定的配置,具体的配置目前应该没必要深究。可以看到使用默认配置是将loadDefault这个bool值设为false,然后往一个WeakHashMap中put一个key为自己,value为null的键值对。
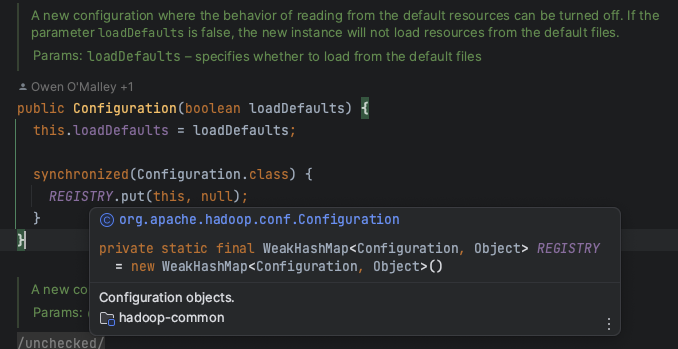
第一次看到WeakHashMap,学一下。
这里使用的原因,应该是为了没有地方继续使用Configuration时可以让垃圾回收机自动回收这个entry,Configuration应该是一个比较大的对象。有几个问题,第一,什么时候Configuration会不再有对象引用呢?第二,这里的map中会存放哪些Configuration呢?第三,是通过把各种不同路径的C configuration都存在这里然后只用其中的部分,剩下的部分如果一直不使用就让垃圾回收器回收吗?
现在可以进入ToolRunner方法中去看了
一上来就是CallerContext.getCurrent(),经常看到一些这种getCurrent的操作,今天仔细盘一下。
进去之后调用的是CurrentCallerContextHolder.CALLER_CONTEXT.get()
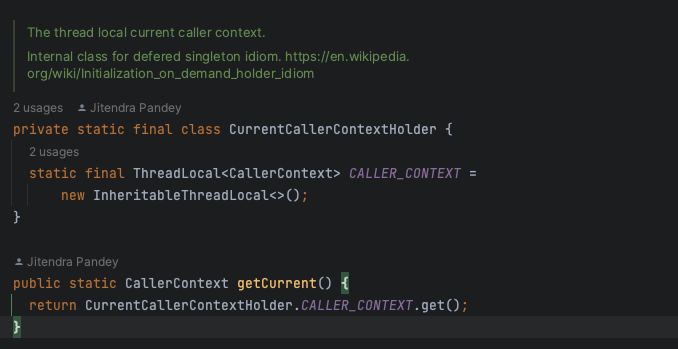
类描述里贴心的给了链接https://en.wikipedia.org/wiki/Initialization-on-demand_holder_idiom
学一下,原来这就是线程安全的单例的使用案例,利用jvm初始化类的特性。
不过这个单例有点变种,返回的是ThreadLocal变量,这部分内容我还是有点生疏。
学习一下ThreadLocal
我现在理解的是ThreadLocal给每个线程属于自己的对象,
ThreadLocal表示线程的“局部变量”,它确保每个线程的ThreadLocal变量都是各自独立的;ThreadLocal适合在一个线程的处理流程中保持上下文(避免了同一参数在所有方法中传递;https://www.liaoxuefeng.com/wiki/1252599548343744/1306581251653666
而inheritableThreadLocal会让每个子进程继承父进程的threadlocal
CallerContext是一个单例,使用线程安全的单例模式,CALLER_CONTEXT这个线程变量就是实例,那就是说CallerContext在每个线程中只存放一份。
再回到ToolRunner的run方法,通过getCurrent()获取当前线程的CallerContext,第一次应该没有(因为没有写initValue方法),所以手动构造一个CallerContext。CallerContext中还有个建造者,使用建造者模式build出CallerContext。
这个builder构造函数目前看起来就是简单的把context存起来,当然前面做了一些简单的合法判断。
最终build时设置了context和signature两个变量,目前不是很清楚是干什么的。
好,现在已经有了线程的CallderContext了,接下来是一个CommonAuditContext.noteRntryPoint(tool), 这个函数将类和一个PATAM_COMMAND(字符串)放到一个全局的map中去了,我猜这个应该是开启审计功能的开关?后面审计部分可能会看那个全局表。
然后是再判断conf是不是null,是就再创建一个新的。感觉有点冗余。
接下来创建了一个GenericOptionsParser,这个类是用来解析命令行参数的,其实感觉像开源项目中这种解析命令行参数的类还是值得看得,不然每次命令行参数都用的云里雾里的。里面用了另一个开源的参数解析包CLI,就不细看了。
Grep类继承了Configured,而Configured又实现了COnfigurable接口,所以有setConf()以及Configuration,run方法中把生成的conf给set进了tool自己
set the configuration back, so that Tool can configure itself
最后终于到了grep中的run方法了。